
Davanum Srinivas (dims) and I did a presentation at OpenStack Summit in Sydney. The slides from the presentation are here.
Category: OpenStack
Running for election to the OpenStack TC!
Last week I submitted my candidacy for election to the OpenStack Technical Committee[1], [2].
One thing that I am liking with this new election format is the email exchanges on the OpenStack mailing list to get a sense for candidates points of view on a variety of things.
In a totally non-work, non-technical context, I have participated and helped organize “candidates nights” events where candidates for election actually get to sit in front of an electorate and answer questions; real politics at the grass roots level. Some years back in one such election, I was elected to a position in the town where I live where I am required to lead with no real authority! So I look forward to doing the same with OpenStack.
You can read my candidacy statement at [1] and [2] so I won’t repeat those things here. I continue to work actively on OpenStack at Verizon now. In the past I was not really a “user” of OpenStack, now I absolutely am, and I am also a contributor. I want to build a better and more functional DBaaS solution and the good news is that there are four companies that are already interested in participating in the project; projects that didn’t participate in the Trove project!
I’m looking forward to working on Hoard in the community, and to serving on the TC if you give me that opportunity!
[1] https://review.openstack.org/#/c/510133/
[2] http://openstack.markmail.org/thread/y22fyka77yq7m3uj
Reflections on the (first annual) OpenDev Conference, SFO
Earlier this week, I attended the OpenDev conference in San Francisco, CA.
The conference was focused on the emerging “edge computing” use cases for the cloud. This is an area that is of particular interest, not just from the obvious applicability to my ‘day job’ at Verizon, but also from the fact that it opens up an interesting new set of opportunities for distributed computing applications.
The highlight(s) of the show were two keynotes by M. Satyanarayanan of CMU. Both sessions were video taped and I’m hoping that the videos will be made available soon.
His team is working on some real cool stuff, and he showed off some of their work. The one that I found most fascinating, which most completely illustrates the value of edge computing is the augmented reality application to playing table tennis (which they call ping pong, and I know that annoys a lot of people :))
It was great to hear a user perspective presented by Andrew Mitry of Walmart. With 11,000 stores and an enormous (2mm??) employees, their edge computing use-case truly represents the scale at which these systems will have to operate, and the benefits that they can bring to the enterprise.
The conference sessions were very interesting and some of my key takeaways were that:
- Edge Computing means different things to different people, because the term ‘Edge’ means different things to different applications. In some cases the edge device may be in a data center, in other cases in your houses, and in other cases on top of a lamp post at the end of your street.
- A common API in orchestrating applications across the entirety of the cloud is very important, but different technologies may be better suited to each location in the cloud. There was a lot of discussion of the value (or lack thereof) of having OpenStack at the edge, and whether it made sense for edge devices to be orchestrated by OpenStack (or not).
- I think an enormous amount of time was spent on debating whether or not OpenStack could be made to fit on a system with limited resources and I found this discussion to be rather tiring. After all, OpenStack runs fine on a little raspberry-pi and for a deployment where there will be relatively few OpenStack operations (instance, volume, security group creation, update, deletetion) the limited resources at the edge should be more than sufficient.
- There are different use-cases for edge-computing and NFV/VNF are not the only ones, and while they may be the early movers into this space, they may be unrepresentative of the larger market opportunity presented by the edge.
There is a lot of activity going on in the edge computing space and many of the things we’re doing at Verizon fall into that category. There were several sessions that showcased some of the things that we have been doing, AT&T had a couple of sessions describing their initiatives in the space as well.
There was a very interesting discussion of the edge computing use-cases and the etherpad for that session can be found here.
Some others who attended the session also posted summaries on their blogs. This one from Chris Dent provides a good summary.
A conclusion/wrap-up session identified some clear follow-up activities. The etherpad for that session can be found here.
Troubleshooting OpenStack gate issues with logstash
From time to time, I have to figure out why the Trove CI failed some job. By “from to time”, I really mean “constantly”, “all the time”, and “everyday”.
Very often the issue is some broken change that someone pushed up, easy ones are pep8 or pylint failures, slightly harder are the py27/py35 failures. The really hard ones are failures in the Trove scenario tests.
Very often the failures are transient and a recheck fixes them (which is annoying in itself) but sometimes the failure is repeatable.
In the past week, I’ve had to deal with one such issue; I first realized that it was a repeated failure after about a dozen rechecks of various changes.
I realized that the change had a telltale signature that looked like this:
Test Replication Instance Multi-Promote functionality. Test promoting a replica to replica source (master). SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320> Verify data is still on new master. SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320> Add data to new master to verify replication. SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320> Verify data exists on new master. SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320>
The important part of the message (I realized later) was the part that read:
Failure in <function wait_for_delete_non_affinity_master ...
Looking a bit above this, I found the test that had in fact failed
Wait for the non-affinity master to delete. FAIL
One thing important in this kind of debugging is to try and figure out when this failure really started to happen, and that’s one of the places where logstash comes in really handy.
For every single CI job run by the OpenStack integrated gate, the result artifacts are parsed and some of them are indexed in an elasticsearch database.
It is trivial now to pick up the string that I felt was the ‘signature’ and search for it in logstash. Within seconds I can tell that this error began to occur on 4/11.

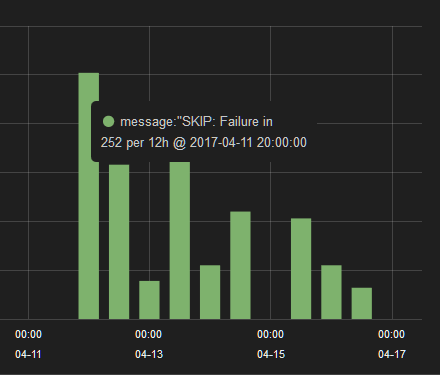 This, by itself was not sufficient to figure out what the problem was, but once Matt Riedemann identified a probable cause, I was able to confirm that the problem started occurring shortly after that change merged.
This, by itself was not sufficient to figure out what the problem was, but once Matt Riedemann identified a probable cause, I was able to confirm that the problem started occurring shortly after that change merged.
Logstash is a really really powerful tool, give it a shot, you’ll find it very useful.
Reflections on the first #OpenStack PTG (Pike PTG, Atlanta)
A very long time ago, and on a planet very unlike the earth we are on now, Thierry sent this email [1] proposing that after Barcelona, let’s split the OpenStack Summit into what have now come to be known as the Design Summit and a Forum. The email thread that resulted from [1] was an active one and had 125 responses, along the way Thierry also posted [2], a summary of the issues and concerns raised.
I had my reservations about the idea, and now, after returning from the first of these, have had some time to reflect on the result.
On the whole, the event was very well done, and I believe that everyone who attended the feedback session had positive things to say about the event, and my congratulations to Erin Disney and the rest of the team at the Foundation. The attendance was a solid 500 to 600 people (I don’t know the exact number) and Thierry must be psychic because he predicted almost exactly that in February [3].
 I did not realize that the foundation had gone as far as to get Starbucks to customize a blend of coffee for us, and to get the Sheraton to distribute in our rooms (image courtesy of Masayuki Igawa, @masayukig).
I did not realize that the foundation had gone as far as to get Starbucks to customize a blend of coffee for us, and to get the Sheraton to distribute in our rooms (image courtesy of Masayuki Igawa, @masayukig).
The format gave attendees the opportunity to get a significant amount of work done both within their own project teams, as well as with other project teams, without the interruptions and distractions of the summit.
I particularly liked the fact that I could attend two days of cross project sessions and then two and a half days of sessions with other projects. By giving projects two or three room-days instead of four or five room-hours dramatically improved the amount of time that projects could focus on their own discussions, and spend on cross project discussions.
Personally, I think the PTG was a success, and seems to have delivered most if not all of the things that it set out to do. Some things outside of our control, certainly outside the control of the foundation have cast a small shadow on the proceedings and we need to seriously consider the consequences of where the next summit and PTG’s are. The location has implication for many attendees, and I think we should seriously consider having remote participation at future events.
From my recollection of the feedback session (unfortunately I don’t have a link to the etherpad, if someone has it, please post a comment with it) everyone had good things to say about the event as a whole. The consensus was that the food was good but cold sandwiches get boring after day 3, the air handlers were noisy, the rooms were too cold (or hot), the chairs were uncomfortable, and there was no soda. That feedback is consistent with organizing an event for 500 people in a hotel or convention facility anywhere in the world. And if that’s all that people could put down in the “needs improvement” section, the event was a huge success.
 I think the award for the best picture at the summit (thanks to Thierry for the tweet) goes to the Designate team[4]. I should’ve thought to get a Trove team photo while we were there!
I think the award for the best picture at the summit (thanks to Thierry for the tweet) goes to the Designate team[4]. I should’ve thought to get a Trove team photo while we were there!
[1] http://markmail.org/thread/v6h3qzs7rb35h6fo
[2] http://markmail.org/message/slzcvunoxccse5k4
[3] http://markmail.org/message/bultywgyxued5khl
[4] https://twitter.com/tcarrez/status/835149239571316736/photo/1
Automating OpenStack’s gerrit commands with a CLI
Every OpenStack developer has to interact with the gerrit code review system. Reviewers and core reviewers have to do this even more, and PTL’s do a lot of this.
The web-based interface is not conducive to many of the more common things that one has to do while managing a project and early on, I started using the gerrit query CLI.
Along the way, I started writing a simple CLI that I could use to automate more things and recently a few people asked about these tools and whether I’d share.
I’m not claiming that this is unique, or that this hasn’t been done before; it evolved slowly and there may be a better set of tools out there that does all of this (and more). I don’t know about them. If you have similar tools, please do share (comment below).
So, I’ve cleaned up this tools a bit (removed things like my private key, username and password) and made them available here.
Full disclosure, they are kind of rough at the edges and you could cause yourself some grief if you aren’t quite sure what you are doing.
Here’s a quick introduction
Installation
It should be nothing more than cloning the repository git@github.com/amrith/gerrit-cli and running the install command. Note, I use python 2.7 as my default python on Ubuntu 16.04. If you use python 3.x, your mileage may vary.
Simple commands
The simplest command is ‘ls’ to list reviews
gerrit-cli ls owner:self
As you can see, the search here is a standard gerrit query search.
You don’t have to type complex queries everytime, you can store and reuse queries. A very simple configuration file is used for this (a sample configuration file is also provided and gets installed by default).
amrith@amrith-work:~$ cat .gerrit-cli/gerrit-cli.json
{
# global options
"host": "review.openstack.org",
"port": 29418,
# "dry-run": true,
# user defined queries
"queries": {
# each query is necessarily a list, even if it is a single string
"trove-filter": ["(project:openstack/trove-specs OR project:openstack/trove OR project:openstack/trove-dashboard OR project:openstack/python-troveclient OR project:openstack/trove-integration)"],
# the simple filter uses the trove-filter and appends status:open and is therefore a list
"simple": ["trove-filter", "status:open"],
"review-list": ["trove-filter", "status:open", "NOT label:Code-Review>=-2,self"],
"commitids": ["simple"],
"older-than-two-weeks": ["simple", "age:2w"]
},
# user defined results
"results": {
# each result is necessarily a list, even if it is a single column
"default": ["number:r", "project:l", "owner:l", "subject:l:80", "state", "age:r"],
"simple": ["number:r", "project:l", "owner:l", "subject:l:80", "state", "age:r"],
"commitids": [ "number:r", "subject:l:60", "owner:l", "commitid:l", "patchset:r" ],
"review-list": [ "number:r", "project:l", "branch:c", "subject:l:80", "owner:l", "state", "age:r" ]
}
}
The file is a simple JSON and you can comment lines just as you would in python (#…)
Don’t do anything, just – – dry-run
The best way to see what’s going on is to use the –dry-run command (or to be sure, uncomment the line in your configuration file).
amrith@amrith-work:~$ gerrit-cli --dry-run ls owner:self ssh review.openstack.org -p 29418 gerrit query --format=JSON --current-patch-set --patch-sets --all-approvals owner:self +--------+---------+-------+---------+-------+-----+ | Number | Project | Owner | Subject | State | Age | +--------+---------+-------+---------+-------+-----+ [...] +--------+---------+-------+---------+-------+-----+
So the owner:self query makes a gerrit query and formats and displays the output as shown above.
So, what columns are displayed? The configuration contains a section called “results” and a default result is defined there.
"default": ["number:r", "project:l", "owner:l", "subject:l:80", "state", "age:r"],
You can override the default and cause a different set of columns to be shown. If a default is not found, the code has a hardcoded default as well.
Similarly, you could run the query:
amrith@amrith-work:~$ gerrit-cli --dry-run ls ssh review.openstack.org -p 29418 gerrit query --format=JSON --current-patch-set --patch-sets --all-approvals owner:self status:open +--------+---------+-------+---------+-------+-----+ | Number | Project | Owner | Subject | State | Age | +--------+---------+-------+---------+-------+-----+ +--------+---------+-------+---------+-------+-----+
and a default query will be generated for you, that query is owner:self and status:open.
You can nest these definitions as shown in the default configuration.
amrith@amrith-work:~$ gerrit-cli --dry-run ls commitids ssh review.openstack.org -p 29418 gerrit query --format=JSON --current-patch-set --patch-sets --all-approvals (project:openstack/trove-specs OR project:openstack/trove OR project:openstack/trove-dashboard OR project:openstack/python-troveclient OR project:openstack/trove-integration) status:open +--------+---------+-------+---------+-------+-----+ | Number | Project | Owner | Subject | State | Age | +--------+---------+-------+---------+-------+-----+ +--------+---------+-------+---------+-------+-----+
The query “commitids” is expanded as follows.
commitids -> simplesimple -> trove-filter, statusopentrove-filter -> (...)
What else can I do?
You can do a lot more than just list reviews …
amrith@amrith-work:~$ gerrit-cli --help
usage: gerrit [-h] [--host HOST] [--port PORT] [--dry-run]
[--config-file CONFIG_FILE] [-v]
{ls,show,update,abandon,restore,recheck} ...
A simple gerrit command line interface
positional arguments:
{ls,show,update,abandon,restore,recheck}
ls list reviews
show show review(s)
update update review(s)
abandon abandon review(s)
restore restore review(s)
recheck abandon review(s)
optional arguments:
-h, --help show this help message and exit
--host HOST The gerrit host. Default: review.openstack.org
--port PORT The gerrit port. Default: 29418
--dry-run Whether or not to actually execute commands that
modify a review.
--config-file CONFIG_FILE
The path to the gerrit-cli configuration file to use
for this session. (Default: ~/.gerrit-cli/gerrit-
cli.json
-v, --verbose Provide additional (verbose) debug output.
Other things that I do quite often (and like to automate) are update, abandon, restore and recheck.
A word of caution: when you aren’t sure what the command will do, use –dry-run. Otherwise, you could end up in a world of hurt.
Like, when you accidentally abandon a 100 reviews 🙂
And even if you know what your query should do, remember I’ve hidden some choice bugs in the code. You may hit those too.
Enjoy!
I’ll update the readme with more information when I get some time.
Effective OpenStack contribution: Seven things to avoid at all cost
There are numerous blogs and resources for the new and aspiring OpenStack contributor, providing tips, listing what to do. Here are seven things to avoid if you want to be an effective OpenStack contributor.
I wrote one of these.
There have been presentations at summits that share other useful newbie tips as well, here is one.
Project repositories often include a CONTRIBUTING.rst file that shares information for newcomers. Here is the file for the Trove project.
Finally, many of these resources include a pointer to the OpenStack Developer’s Guide.
Over the past three years, I have seen several newbie mistakes repeated over and over again and in thinking about some recent incidents, I think the community has not done a good job documenting these “Don’t Do’s”.
So here is a start; here are seven things you shouldn’t do, if you want to be an effective OpenStack contributor.
1. Don’t submit empty commit messages
 The commit message is a useful part of the commit and it serves to inform reviewers about what the change is, and how your proposed fix addresses the problem. In general, (with the notable exception of procedural commits for things like releases or infrastructure), the commit message should not be empty. The words “Trivial Fix” do not suffice.
The commit message is a useful part of the commit and it serves to inform reviewers about what the change is, and how your proposed fix addresses the problem. In general, (with the notable exception of procedural commits for things like releases or infrastructure), the commit message should not be empty. The words “Trivial Fix” do not suffice.
OpenStack documents best practices for commit messages. Make sure your commit message provides a succinct description of the problem, describes how you propose to fix it, and includes a reference (via the Close-Bug, Partial-Bug or Related-Bug tags) to the Launchpad entry for the issue you are fixing.
2. Don’t expect that reviews are automatic
In OpenStack, reviewing changes is a community activity. If you propose changes, they get merged because others in the community contribute their time and effort in reviewing your changes. This wouldn’t work unless everyone participates in the review process.
Just because you submitted some changes, don’t expect others to feel motivated or obligated to review your changes. In many projects, review bandwidth is at a premium and therefore you will have a better chance getting your change reviewed and approved if you reciprocate and review other people’s changes.
3. Don’t leave empty reviews
 When you review someone’s code, merely adding a +1 serves no useful purpose. At the very least indicate what you did with the change. Equally useful is to say what you did not do.
When you review someone’s code, merely adding a +1 serves no useful purpose. At the very least indicate what you did with the change. Equally useful is to say what you did not do.
For example, you could indicate that you only reviewed the code and did not actually test it out. Or you could go further and download and test the patch set and indicate in your review comment that you tested the change and found it to work. On occasion, such as when I review a change for the first time, I will indicate that I have reviewed the changes but not the tests.
Feel free to ask questions about the change if you don’t follow what is being done. Also, feel free to suggest alternate implementations if you feel that the proposed implementation is not the best one for some reason(s).
Don’t feel shy about marking changes with a -1 if you feel that it is not ready to merge for some reason.
A drive-by +1 is a generally unhelpful activity, and if you persist at doing that, others in the community will tend to discount your reviews anyway.
4. Don’t game the Stackalytics system
 By far, the most egregious violation that I’ve seen is when people blatantly try to game the Stackalytics system. Stackalytics is a tool that tracks individual and company participation in OpenStack.
By far, the most egregious violation that I’ve seen is when people blatantly try to game the Stackalytics system. Stackalytics is a tool that tracks individual and company participation in OpenStack.
Here, for example, is the Stackalytics page for the Trove project in the current release:
Reviews: http://stackalytics.com/?module=trove-group
Commits: http://stackalytics.com/?module=trove-group&metric=commits
It allows you to see many metrics in a graphical way, and allows you to slice and dice the data in a number of interesting ways.
New contributors, bubbling with enthusiasm often fall into the trap of trying to game the system and rack up reviews or commits. This can end up very badly for you if you go down this route. For example, recently one very enthusiastic person showed up with a change that got blasted out to about 150 projects, and attempted to add a CONTRIBUTING.rst file to all of these projects. What ensued is documented in this mailing list thread:
A few of the changes were merged before they were reverted, the vast majority were abandoned.
Changes like this serve no real useful purpose. They also consume an inordinate amount of resources in the CI system. I computed that the little shenanigan described above generated approximately 1050 CI jobs and consumed about 190 hours of time on the CI system.
I admit that numbers are important and they are a good indication of participation. But quality is a much more important metric because quality is an indicator of contribution. And I firmly believe that participation is about showing up, contribution is about what you do once you are here, and contribution is a way more important thing to aim for than participation.
5. Don’t ignore review comments
Finally, when you’ve submitted a change, and people review and provide comments, don’t ignore them. If you are serious about a change, you will stay with it till it gets merged. Respond to comments in a timely manner, if only to say that you will come back with a new patch set in some time.
If you don’t, remember that review bandwidth is a scarce resource and in the future your changes may get scant attention from reviewers. Others who review your changes are taking time out of their schedules to participate in the community. At the very least you should recognize and respect that investment on their part and reciprocate with timely responses.
6. Don’t be shy
And above all, if you aren’t sure how to proceed, don’t be shy. Post a question on the mailing list if you aren’t sure what to do about something. If that’s too public for you (and that’s perfectly alright), ask the question on the IRC channel for the project in question. If that is too public, find someone who is active on the project (start with the PTL) and send that person an email.
An important aspect of the role of a PTL is fielding those questions, and all of us (PTL’s) receive several of these questions each month. Not sure whom to ask, then toss the question out on IRC at #openstack or #openstack-dev and you should receive an answer before long.
7. Don’t be an IRC ghost
 An important thing to remember about IRC is that it is an asynchronous medium. So, don’t expect answers in real time. The OpenStack community is highly distributed, but also most active during daylight hours, Monday to Friday in US time. If you pop up on IRC, ask a question and then disappear, you may not get your answer. If you can’t stick around for a long time on IRC, then post your question to the mailing list.
An important thing to remember about IRC is that it is an asynchronous medium. So, don’t expect answers in real time. The OpenStack community is highly distributed, but also most active during daylight hours, Monday to Friday in US time. If you pop up on IRC, ask a question and then disappear, you may not get your answer. If you can’t stick around for a long time on IRC, then post your question to the mailing list.
But better still, there are many ways in which you can connect to IRC and leave the connection up (so you can read the scrollback), or find some other mechanism to review the scrollback (like eavesdrop.openstack.org) to see if your question was answered.
If you have your own pet peeve, please share it in the comments section. I hope this will become a useful resource for aspiring OpenStack contributors.
Addressing a common misconception regarding OpenStack Trove security
Since my first OpenStack Summit in Atlanta (mid 2014), I have been to a number of OpenStack-related events, meetups, and summits. And at every one of these events, as well as numerous customer and prospect meetings, I’ve been asked some variant of the question:
Isn’t Trove insecure because the guestagent has RabbitMQ credentials?
A bug was entered in 2015 with the ominous (and factually inaccurate) description that reads “Guestagent config leaks rabbit password”.
And while I’ve tried to explain to people that this is not at all the case, this misconception has persisted.
At the Summit in Barcelona, I was asked yet again about this and I realized that obviously, whatever we in the Trove team had been doing to communicate the reality was insufficient. So, in preparation for the upcoming Summit in Boston, I’m writing this post as a handy resource.
What is the problem?
Shown here is a simplified representation of a Trove system with a single guest database instance. The control plane components (Trove API, Trove Task Manager, and Trove Conductor) and the Guest Agent communicate via oslo.messaging which is typically implemented with some messaging transport like RabbitMQ.
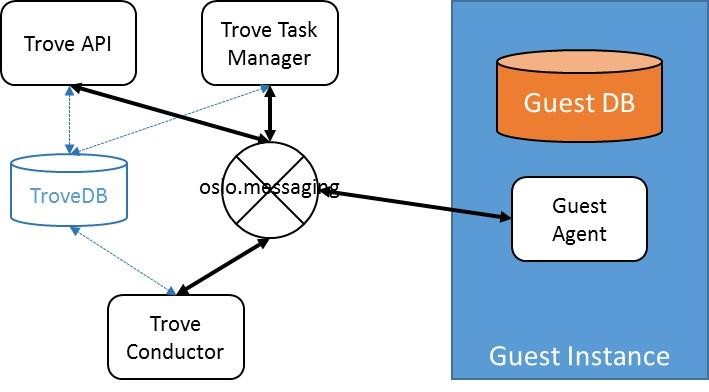 To connect to the underlying transport, each of these four components needs to store credentials; for RabbitMQ this is a username and password.
To connect to the underlying transport, each of these four components needs to store credentials; for RabbitMQ this is a username and password.
The contention is that if a guest instance is somehow compromised (and there are many ways to do this) and a bad actor gains access to the RabbitMQ credentials, then the OpenStack deployment is compromised.
Why is this not really a problem?
Here are some reasons this is not really an issue on a properly configured production system.
- Nothing requires that Trove use the same RabbitMQ servers as the rest of OpenStack. So at the very least, the compromise can be limited to the RabbitMQ servers used by Trove.
- The guest instance is not intended to be a general-purpose instance that a user has access to; in the intended deployment, the only connectivity to the guest instance would be to the database ports for queries. These are configurable with each database (datastore) and enforced by Neutron. Shell access (port 22, ssh) is a no-no. No deployer would use images and configurations that allowed this kind of access.
- On the guest instance, other database specific best practices are used to prevent shell escapes and other exploits that will give a user access to the RabbitMQ credentials.
- Guest instances can be spawned by Trove using service credentials, or credentials for a shadow tenant to prevent an end user from directly accessing the underlying Nova instance. Similarly Cinder volumes can be provisioned with a different tenant to prevent an end user from directly accessing the underlying volume.
All of this notwithstanding, the urban legend was that Trove was a security risk. The reason invariably involved a system configured by devstack, with a single RabbitMQ, open access to port 22 on the guest, run in the same tenant as the requestor of the database.
Yet, one can safely say that no one in their right mind would operate OpenStack as configured by devstack in production. And certainly, with Trove, one would not use the development images whose elements are part of the source tree in a production deployment.
proposed security related improvements in Ocata
In the Ocata release, one additional set of changes has been made to further secure the system. All RPC calls on the oslo.messaging bus are completely encrypted. Furthermore, different conversations are encrypted using unique encryption keys.
 The messaging traffic on oslo.messaging is solely for oslo_messaging.rpc, the OpenStack Remote Procedure Call mechanism. The API service makes calls into the Task Manager, the Task Manager makes calls into the Guest Agent, and the Guest Agent makes calls into the Conductor.
The messaging traffic on oslo.messaging is solely for oslo_messaging.rpc, the OpenStack Remote Procedure Call mechanism. The API service makes calls into the Task Manager, the Task Manager makes calls into the Guest Agent, and the Guest Agent makes calls into the Conductor.
The picture above shows these different conversations, and the encryption keys used on each. When the API service makes an RPC call to the Task Manager, all parameters to the call are encrypted using K1 which is stored securely on the control plane.
Unique encryption keys are created for each guest instance, and these keys are used for all communication. When the Task Manager wishes to make a call to Guest Agent 1, it uses the instance specific key K2, and when it wants to make a call to Guest Agent 2, it uses the instance specific key K3. When the guest agents want to make calls to the Conductor, the traffic is encrypted using the instance specific keys and the conductor decrypts the parameters using those instance specific keys.
In a well configured production deployment, one that takes steps to secure the system, if a bad actor were to compromise a guest instance (say Guest Agent 1) and get access to K2 and the RabbitMQ Credentials, the user could access RabbitMQ but would not be able to do anything to impact either another guest instance (he wouldn’t have K3) or the Task Manager (he wouldn’t have K1).
Code that implements this capability is currently in upstream review.
This blog post resulted in a brief twitter exchange with Adam Young (@admiyoung)
@amrithkumar broker provides encryption.
What oslomsg needs is authentication and authorization: https://t.co/U110mZNtUR— Adam Young (@admiyoung) January 9, 2017
@admiyoung agreed, been there, and couldn’t get that; hence this implementation is all that’s left … https://t.co/uOS6CTnrxl
— amrith (@amrithkumar) January 9, 2017
@amrithkumar You should be able to get there for Trove, though: Separate user, domain etc. No?
— Adam Young (@admiyoung) January 9, 2017
Unfortunately, a single user (in RabbitMQ) for Trove isn’t the answer. Should a guest get compromised, then those credentials are sufficient to post messages to RabbitMQ and cause some amount of damage.
One would need per guest instance credentials to avoid this; or one of the many other solutions (like shadow tenants, etc).
Enabling hacking extensions: The right way
Of late, I wake up every morning revving to go and work on the next cool thing in Trove and I see that overnight some well-meaning person has contributed a change that looks something like this:
String interpolation should be delayed to be handled by the logging code, rather than being done at the point of the logging call.
Ref:http://docs.openstack.org/developer/oslo.i18n/guidelines.html#log-translation For example:
# WRONG
LOG.info(_LI(‘some message: variable=%s’) % variable)
# RIGHT
LOG.info(_LI(‘some message: variable=%s’), variable)
And the code submitted fixes a small number (lets say 5) places where strings sent to logging are rendered.
As I said at the TC-Board meeting in Barcelona, these well-meaning people are actually submitting what on the face of it appear to be valid corrections to the code. Yet, I submit to you that these changes represent a scourge that we should stamp out.
I know for a fact that in Trove there are (currently) 751 occurrences of this particular style error. This is the hacking extension H904, and when enabled in Trove, I get this:
$ tox -e pep8 | grep H904 | wc -l
751
That’s the catch, Trove does not enable this hacking extension. A quick look indicates that only Neutron does.
Why are these well meaning changes a scourge? Here’s why …
- They don’t materially improve a project to fix a small fraction of these errors without preventing them from reoccurring
- Each of these changes takes some considerable CI resources to verify and get approved
- Each of these changes take time for someone to review, time which could be better spent if we were to fix these problems properly.
So, I submit to you that if you want to submit a patch to fix one of these hacking issues, here is the right way. Of course, I’m opinionated, I’m going to reference one of my own changes as an example!
- If your project does not have hacking extensions, this commit shows you what you have to do to enable that. You may have to bump test-requirements.txt and update the version of hacking that you use in order to use the ‘enable-extensions’ option.
- Enable the hacking rule or extension for the particular style issue at hand; let’s illustrate with H203. H203 ensures that we use assertNone() and not assertEqual(None, …).
- Run the pep8 test against the project and find and correct all places where the failure occurs. Typically this is accomplished by just running ‘tox -e pep8’.
- Test that the code does in fact work as expected; correcting style guidelines can introduce functional errors so make sure that the unit tests pass too. Typically this is accomplished by running ‘tox -e py27 -e py34’.
- Actually exercise the system; launch a system with devstack and the project enabled, and actually exercise the system. In the case of Trove, actually build a guest and launch a database or two.
- Then submit your change including the change to tox.ini that enables the hacking rule for review.
Well, that’s a lot of work! Sure, you really have to work for your Stackalytics credit, right? I’m sure the load on the CI system will show that this is worthwhile.
It is better to do things this way in the long run. With the hacking rule enabled, future commits will also comply with the rule (they will fail pep8 if they don’t). And that will put an end to the cottage industry that has sprung up around finding these kinds of errors and fixing them one at a time.
In conclusion I urge reviewers in all projects to summarily reject style changes that don’t also enable a hacking rule. Approving them is the wrong thing to do. Require the contributor to enable the hacking rule, and fix the problem the right way. That’s what a good code review is about.
My adventures with pylint
I have long believed that it is ok to make any given mistake once. But to make it again is, I believe, unforgivable.
This should, I believe, apply to all things that we do as software developers, and to that end, I feel that code changes to fix issues should be backed up in some way by testing that prevents recurrence of problems.
In my day job, I work on the OpenStack Trove project, and when I review changes proposed by others, I tend to apply this yardstick. When someone fixes a line of code to correct some issue, it is common to expect that there will be a test to verify this operation in the future.
Recently, I reviewed and approved a change that pretty immediately resulted in a regression. Here’s the diff of the code in question:
if not manager:
- msg = ("Manager class not registered for datastore manager %s" %
+ msg = (_LE("Manager class not registered for datastore manager %s") %
CONF.datastore_manager)
raise RuntimeError(msg)
Not being a compiled language, and since no tests exist for the case where manager is None, this code was never exercised, and _LE was not defined. Sure enough a couple of days later, the regression was reported.
This got me wondering how the problem could be avoided. Surely python must have some tools to catch this kind of thing. How did this escape the development process (obvious explanation of sloppy code review aside).
It turns out that there is a mechanism to catch these kinds of things, pylint. And it turns out that we don’t use pylint very much in OpenStack.
Well, a short while later I was able to run my little pylint based wrapper on Trove and fix some egregious bugs.
pylint doesn’t natively give you a way to provide a specific set of issues that must be ignored (something which bandit does). So I modeled this wrapper on the way bandit does things and allowed for a set of ignored exceptions.
I’ll make this a job in the Trove gate soon and that will help stamp out these kinds of issues more quickly.
Debugging Trove gate failures
Of late, I’ve spent a fair amount of time debugging Trove’s gate failures. And this isn’t the first time, it generally happens around release time. And each time, I relearn the same things. So this time, I’ll make a note of what I’ve done recently. Hopefully, it’ll ease the process next time.
Leading India e-commerce site launches OpenStack hybrid cloud
This is huge news!
Leading India e-commerce site launches OpenStack hybrid cloud
Just to give you a sense of the size of this company, consider this:
Snapdeal has already cornered about a quarter of the Indian e-commerce market, that’s twice as much as Amazon but about half of its largest local competitor Flipkart, in what some are calling the “great race” to rule what may become the world’s largest online marketplace. With the fastest growing e-commerce market, Snapdeal reaches people that brick-and-mortar businesses can’t, since half of its customers live outside India’s biggest cities.
Expanding DBaaS workloads with OpenStack Trove and Manila
In this interview, learn more about how OpenStack’s Trove and Manila projects are adapting to meet the varied database needs of cloud users..
Source: Expanding DBaaS workloads with OpenStack Trove and Manila
Utilizing OpenStack Trove DBaaS for deployment management
Ron Bradford posted this interesting article on his blog after a recent trip I made to New York City.
Trove is used for self service provisioning and lifecycle management for relational and non-relational databases in an OpenStack cloud.. Trove provides a RESTful API interface that is same regardless of the type of database.. CLI tools and a web UI via Horizon are also provided wrapping Trove API requests..
Source: Utilizing OpenStack Trove DBaaS for deployment management
Get Started with OpenStack – 5 Easy Steps
This post appeared first at the Tesora blog.
I was recently asked what resources I would recommend to someone looking to get started with OpenStack. I’d like to provide them here for those who may be beginning their OpenStack journey.
Continue reading “Get Started with OpenStack – 5 Easy Steps”
