
From time to time, I have to figure out why the Trove CI failed some job. By “from to time”, I really mean “constantly”, “all the time”, and “everyday”.
Very often the issue is some broken change that someone pushed up, easy ones are pep8 or pylint failures, slightly harder are the py27/py35 failures. The really hard ones are failures in the Trove scenario tests.
Very often the failures are transient and a recheck fixes them (which is annoying in itself) but sometimes the failure is repeatable.
In the past week, I’ve had to deal with one such issue; I first realized that it was a repeated failure after about a dozen rechecks of various changes.
I realized that the change had a telltale signature that looked like this:
Test Replication Instance Multi-Promote functionality. Test promoting a replica to replica source (master). SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320> Verify data is still on new master. SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320> Add data to new master to verify replication. SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320> Verify data exists on new master. SKIP: Failure in <function wait_for_delete_non_affinity_master at 0x7f1aafd53320>
The important part of the message (I realized later) was the part that read:
Failure in <function wait_for_delete_non_affinity_master ...
Looking a bit above this, I found the test that had in fact failed
Wait for the non-affinity master to delete. FAIL
One thing important in this kind of debugging is to try and figure out when this failure really started to happen, and that’s one of the places where logstash comes in really handy.
For every single CI job run by the OpenStack integrated gate, the result artifacts are parsed and some of them are indexed in an elasticsearch database.
It is trivial now to pick up the string that I felt was the ‘signature’ and search for it in logstash. Within seconds I can tell that this error began to occur on 4/11.

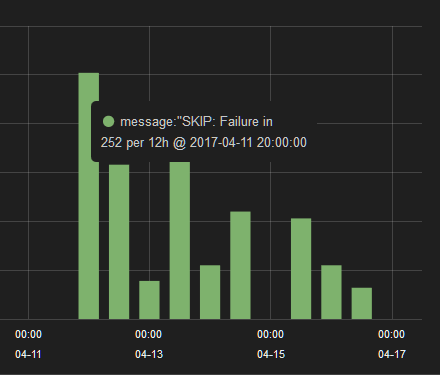 This, by itself was not sufficient to figure out what the problem was, but once Matt Riedemann identified a probable cause, I was able to confirm that the problem started occurring shortly after that change merged.
This, by itself was not sufficient to figure out what the problem was, but once Matt Riedemann identified a probable cause, I was able to confirm that the problem started occurring shortly after that change merged.
Logstash is a really really powerful tool, give it a shot, you’ll find it very useful.

One thought on “Troubleshooting OpenStack gate issues with logstash”