
Since my first OpenStack Summit in Atlanta (mid 2014), I have been to a number of OpenStack-related events, meetups, and summits. And at every one of these events, as well as numerous customer and prospect meetings, I’ve been asked some variant of the question:
Isn’t Trove insecure because the guestagent has RabbitMQ credentials?
A bug was entered in 2015 with the ominous (and factually inaccurate) description that reads “Guestagent config leaks rabbit password”.
And while I’ve tried to explain to people that this is not at all the case, this misconception has persisted.
At the Summit in Barcelona, I was asked yet again about this and I realized that obviously, whatever we in the Trove team had been doing to communicate the reality was insufficient. So, in preparation for the upcoming Summit in Boston, I’m writing this post as a handy resource.
What is the problem?
Shown here is a simplified representation of a Trove system with a single guest database instance. The control plane components (Trove API, Trove Task Manager, and Trove Conductor) and the Guest Agent communicate via oslo.messaging which is typically implemented with some messaging transport like RabbitMQ.
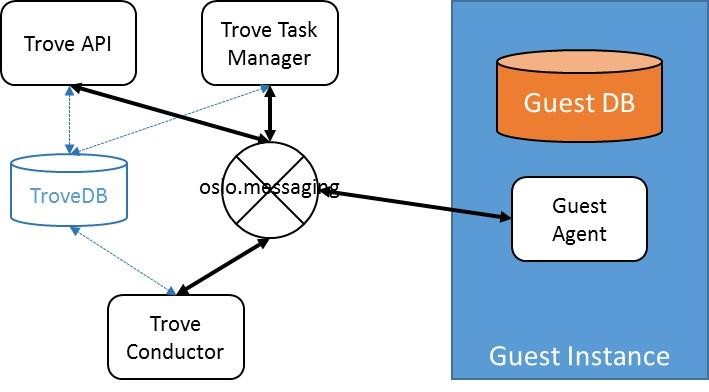 To connect to the underlying transport, each of these four components needs to store credentials; for RabbitMQ this is a username and password.
To connect to the underlying transport, each of these four components needs to store credentials; for RabbitMQ this is a username and password.
The contention is that if a guest instance is somehow compromised (and there are many ways to do this) and a bad actor gains access to the RabbitMQ credentials, then the OpenStack deployment is compromised.
Why is this not really a problem?
Here are some reasons this is not really an issue on a properly configured production system.
- Nothing requires that Trove use the same RabbitMQ servers as the rest of OpenStack. So at the very least, the compromise can be limited to the RabbitMQ servers used by Trove.
- The guest instance is not intended to be a general-purpose instance that a user has access to; in the intended deployment, the only connectivity to the guest instance would be to the database ports for queries. These are configurable with each database (datastore) and enforced by Neutron. Shell access (port 22, ssh) is a no-no. No deployer would use images and configurations that allowed this kind of access.
- On the guest instance, other database specific best practices are used to prevent shell escapes and other exploits that will give a user access to the RabbitMQ credentials.
- Guest instances can be spawned by Trove using service credentials, or credentials for a shadow tenant to prevent an end user from directly accessing the underlying Nova instance. Similarly Cinder volumes can be provisioned with a different tenant to prevent an end user from directly accessing the underlying volume.
All of this notwithstanding, the urban legend was that Trove was a security risk. The reason invariably involved a system configured by devstack, with a single RabbitMQ, open access to port 22 on the guest, run in the same tenant as the requestor of the database.
Yet, one can safely say that no one in their right mind would operate OpenStack as configured by devstack in production. And certainly, with Trove, one would not use the development images whose elements are part of the source tree in a production deployment.
proposed security related improvements in Ocata
In the Ocata release, one additional set of changes has been made to further secure the system. All RPC calls on the oslo.messaging bus are completely encrypted. Furthermore, different conversations are encrypted using unique encryption keys.
 The messaging traffic on oslo.messaging is solely for oslo_messaging.rpc, the OpenStack Remote Procedure Call mechanism. The API service makes calls into the Task Manager, the Task Manager makes calls into the Guest Agent, and the Guest Agent makes calls into the Conductor.
The messaging traffic on oslo.messaging is solely for oslo_messaging.rpc, the OpenStack Remote Procedure Call mechanism. The API service makes calls into the Task Manager, the Task Manager makes calls into the Guest Agent, and the Guest Agent makes calls into the Conductor.
The picture above shows these different conversations, and the encryption keys used on each. When the API service makes an RPC call to the Task Manager, all parameters to the call are encrypted using K1 which is stored securely on the control plane.
Unique encryption keys are created for each guest instance, and these keys are used for all communication. When the Task Manager wishes to make a call to Guest Agent 1, it uses the instance specific key K2, and when it wants to make a call to Guest Agent 2, it uses the instance specific key K3. When the guest agents want to make calls to the Conductor, the traffic is encrypted using the instance specific keys and the conductor decrypts the parameters using those instance specific keys.
In a well configured production deployment, one that takes steps to secure the system, if a bad actor were to compromise a guest instance (say Guest Agent 1) and get access to K2 and the RabbitMQ Credentials, the user could access RabbitMQ but would not be able to do anything to impact either another guest instance (he wouldn’t have K3) or the Task Manager (he wouldn’t have K1).
Code that implements this capability is currently in upstream review.
This blog post resulted in a brief twitter exchange with Adam Young (@admiyoung)
@amrithkumar broker provides encryption.
What oslomsg needs is authentication and authorization: https://t.co/U110mZNtUR— Adam Young (@admiyoung) January 9, 2017
@admiyoung agreed, been there, and couldn’t get that; hence this implementation is all that’s left … https://t.co/uOS6CTnrxl
— amrith (@amrithkumar) January 9, 2017
@amrithkumar You should be able to get there for Trove, though: Separate user, domain etc. No?
— Adam Young (@admiyoung) January 9, 2017
Unfortunately, a single user (in RabbitMQ) for Trove isn’t the answer. Should a guest get compromised, then those credentials are sufficient to post messages to RabbitMQ and cause some amount of damage.
One would need per guest instance credentials to avoid this; or one of the many other solutions (like shadow tenants, etc).
