What is DynamoDB Local? DynamoDB Local is a downloadable version of Amazon DynamoDB. With it, you can develop and test applications without accessing the DynamoDB web service. It is a great way to get started with DynamoDB.
ddbsh (the DynamoDB shell) is an open source CLI for DynamoDB. You can download it here. We would like to make it easier for you to install and use this tool. A pull request has been submitted to homebrew but it is currently blocked. One of the reasons for this is that the ddbsh github repository is not well enough known.
If you would like to have a homebrew formula for ddbsh, please help!
Yesterday I posted a quick introduction to dynamodb-shell. Let’s go a little bit further today. ddbsh has quit a lot of bells and whistles for creating tables.
ap-south-1> help create table;
CREATE TABLE - Creates a DynamoDB table.
CREATE TABLE [IF NOT EXISTS][NOWAIT] <name>
( attribute_name, attribute_type [,...] )
primary_key billing_mode_and_throughput
[gsi_list] [lsi_list] [streams] [table_class] [tags] ;
attribute_type := NUMBER|STRING|BINARY
primary_key := PRIMARY KEY key_schema
key_schema := ( attribute_name HASH [, attribute_name RANGE])
billing_mode_and_throughput := (BILLING MODE ON DEMAND)|BILLING MODE provisioned)
provisioned := ( RR RCU, WW WCU )
gsi_list := GSI ( gsi_spec )
gsi_spec := gsi [, gsi ...]
gsi := gsi_name ON key_schema index_projection [billing_mode_and_throughput]
index_projection := (PROJECTING ALL) | (PROJECTING KEYS ONLY) | (PROJECTING INCLUDE projection_list)
projection_list := ( attribute [, attribute ...] )
lsi_list := LSI ( lsi_spec )
lsi_spec := lsi [, lsi ...]
lsi := lsi_name ON key_schema index_projection
streams := STREAM ( stream_type ) | STREAM DISABLED
stream_type := KEYS ONLY | NEW IMAGE | OLD IMAGE | BOTH IMAGES
table_class := TABLE CLASS STANDARD | TABLE CLASS STANDARD INFREQUENT ACCESS
tags := TAGS ( tag [, tag ...] )
tag := name : value
Let’s make a table with a GSI and with DynamoDB Streams enabled. Since the CREATE TABLE command included “nowait”, the command completed immediately, and a subsequent describe shows that the table is being created.
ap-south-1> create table if not exists nowait balances ( id string, accttype string, balance number )
ap-south-1> primary key ( id hash, accttype range )
ap-south-1> billing mode provisioned ( 20 rcu, 20 wcu )
ap-south-1> gsi (balancegsi on (accttype hash, balance range) projecting all
ap-south-1> billing mode provisioned ( 20 rcu, 20 wcu ))
ap-south-1> stream (both images);
CREATE
ap-south-1> describe balances;
Name: balances (CREATING)
Key: HASH id, RANGE accttype
Attributes: accttype, S, balance, N, id, S
Created at: 2023-01-26T05:01:41Z
Table ARN: arn:aws:dynamodb:ap-south-1:632195519165:table/balances
Table ID: d84f734e-10e9-4c2d-a946-ed8820b82430
Table size (bytes): 0
Item Count: 0
Billing Mode: Provisioned (20 RCU, 20 WCU)
PITR is Disabled.
GSI balancegsi: ( HASH accttype, RANGE balance ), Provisioned (20 RCU, 20 WCU), Projecting (ALL), Status: CREATING, Backfilling: NO
LSI: None
Stream: NEW_AND_OLD_IMAGES
Table Class: STANDARD
SSE: Not set
ap-south-1>
After a few minutes, the table is created and we can start loading up some data.
But, I do have a GSI on the account type (and balance), so I can do one better. I can attempt the query against the GSI (observe that where I had a table, I now have balances.balancegsi which is how I reference the GSI). This turns into a Query on the index instead of a table scan.
One other thing, let’s assume that I want to transfer some money from one account to another without the source account going negative – how would I do that?
Let’s say that Alice wants to transfer $100 from Checking to Savings. We could do this.
ap-south-1> select * from balances where id = "Alice";
{accttype: Checking, balance: 500, id: Alice}
{accttype: Savings, balance: 200, id: Alice}
ap-south-1> begin;
ap-south-1> update balances set balance = balance - 100 where id = "Alice" and accttype = "Checking" and balance >= 100;
ap-south-1> update balances set balance = balance + 100 where id = "Alice" and accttype = "Savings";
ap-south-1> commit;
COMMIT
ap-south-1> select * from balances where id = "Alice";
{accttype: Checking, balance: 400, id: Alice}
{accttype: Savings, balance: 300, id: Alice}
ap-south-1>
For example, let’s say that Bob wants to give $300 to David. Should that be allowed?
ap-south-1> select * from balances where id = "Bob";
{accttype: Checking, balance: 250, id: Bob}
ap-south-1>
Let’s see what happens if we try …
ap-south-1> begin;
ap-south-1> update balances set balance = balance - 300 where id = "Bob" and balance >= 300 and accttype = "Checking";
ap-south-1> update balances set balance = balance + 300 where id = "David" and accttype = "Savings";
ap-south-1> commit;
Transaction failed. TransactionCanceledException. 3D0KI0CHVS7UDTFDMAQ0E43EINVV4KQNSO5AEMVJF66Q9ASUAAJG. Transaction cancelled, please refer cancellation reasons for specific reasons [ConditionalCheckFailed, None]
ABORT
ap-south-1> select * from balances where id in ("Bob", "David");
{accttype: Checking, balance: 250, id: Bob}
{accttype: Savings, balance: 1000, id: David}
ap-south-1>
The Condition Check Failure is a list of two statuses – the first one failed (ConditionCheckFailed) and the other produced no error. So there you have it,
a table with a GSI and you can query either the table or the GSI (specify table.gsi)
you can do multi-line transactions
you can use functions like IN in the where clause.
In the next blog post I’ll dig further into all that you can do in a WHERE clause.
I’ll leave it up to you to run explain on the transaction and see what it does. Hint, just change “begin” to “explain begin”.
ddbsh is provided for your use on an AS-IS basis. It can delete, and update table data, as well as drop tables. These operations are irreversible. It can perform scans and queries against your data and these can cost you significant money.
You are now at an interactive prompt where you can execute commands. The prompt shows that you are connected to us-east-1 (this is the default). You can override that if you so desire (commands in ~/.ddbsh_config will be automatically executed when you launch ddbsh). You can also dynamically reconnect to another region.
That’s all there is to it. Now let’s get back to us-east-1 and take ddbsh for a spin. Let’s make a table. Commands are terminated with the ‘;’ character.
ap-south-1> connect us-east-1;
CONNECT
us-east-1>
us-east-1> create table ddbsh_demo ( id number )
us-east-1> primary key ( id hash );
CREATE
us-east-1>
The CREATE TABLE command (by default) will wait till the table is created. You can have it submit the request and return with the NOWAIT option (see HELPCREATE TABLE for complete options).
By default it creates a table that is On-Demand (you can also create a table with provisioned billing mode, more about that later).
You can do more fancy things with your query, like this.
us-east-1> select id from ddbsh_demo where v = 4;
{id: 3}
us-east-1> select * from ddbsh_demo where v.c = true;
{id: 5, v: {a:4, b:[10, 11, 12], c:TRUE, d:{x:10, y:10}}}
us-east-1> select * from ddbsh_demo where v.b[1] = 11;
{id: 5, v: {a:4, b:[10, 11, 12], c:TRUE, d:{x:10, y:10}}}
us-east-1>
How about making some changes to the data? That’s easy enough.
us-east-1> update ddbsh_demo set z = 14, v.b[1] = 13 where id = 5;
UPDATE (0 read, 1 modified, 0 ccf)
us-east-1> select * from ddbsh_demo where id = 5;
{id: 5, v: {a:4, b:[10, 13, 12], c:TRUE, d:{x:10, y:10}}, z: 14}
us-east-1>
Careful what you do with ddbsh … if you execute a command without a where clause, it can update more items than you expected. For example, consider this.
us-east-1> select * from ddbsh_demo;
{id: 3, v: 4}
{id: 4, v: "a string value"}
{id: 5, v: {a:4, b:[10, 13, 12, 13, 13], c:TRUE, d:{x:10, y:10}}, z: 14}
us-east-1> update ddbsh_demo set newval = "a new value";
UPDATE (3 read, 3 modified, 0 ccf)
us-east-1> select * from ddbsh_demo;
{id: 3, newval: "a new value", v: 4}
{id: 4, newval: "a new value", v: "a string value"}
{id: 5, newval: "a new value", v: {a:4, b:[10, 13, 12, 13, 13], c:TRUE, d:{x:10, y:10}}, z: 14}
us-east-1>
Equally, you can accidentally delete more data than you expected.
us-east-1> delete from ddbsh_demo;
DELETE (3 read, 3 modified, 0 ccf)
us-east-1> select * from ddbsh_demo;
us-east-1>
There, all the data is gone! Hopefully that’s what I intended.
There’s a lot more that you can do with ddbsh – to see what else you can do, check out the HELP command which lists all commands and provides help on each.
Two final things. First, ddbsh also supports a number of DDL commands (in addition to CREATE TABLE).
us-east-1> show tables;
ddbsh_demo | ACTIVE | PAY_PER_REQUEST | STANDARD | ba3c5574-d3ca-469b-aeb8-4ad8f8df9d4e | arn:aws:dynamodb:us-east-1:632195519165:table/ddbsh_demo | TTL DISABLED | GSI: 0 | LSI : 0 |
us-east-1> describe ddbsh_demo;
Name: ddbsh_demo (ACTIVE)
Key: HASH id
Attributes: id, N
Created at: 2023-01-25T12:15:15Z
Table ARN: arn:aws:dynamodb:us-east-1:632195519165:table/ddbsh_demo
Table ID: ba3c5574-d3ca-469b-aeb8-4ad8f8df9d4e
Table size (bytes): 0
Item Count: 0
Billing Mode: On Demand
PITR is Disabled.
GSI: None
LSI: None
Stream: Disabled
Table Class: STANDARD
SSE: Not set
us-east-1>
Now let’s make some changes.
us-east-1> alter table ddbsh_demo set pitr enabled;
ALTER
us-east-1> alter table ddbsh_demo set billing mode provisioned ( 200 rcu, 300 wcu);
ALTER
us-east-1> alter table ddbsh_demo (v number) create gsi gsi_v on (v hash) projecting all billing mode provisioned ( 10 rcu, 20 wcu );
ALTER
us-east-1> describe ddbsh_demo;
Name: ddbsh_demo (ACTIVE)
Key: HASH id
Attributes: id, N, v, N
Created at: 2023-01-25T12:15:15Z
Table ARN: arn:aws:dynamodb:us-east-1:632195519165:table/ddbsh_demo
Table ID: ba3c5574-d3ca-469b-aeb8-4ad8f8df9d4e
Table size (bytes): 0
Item Count: 0
Billing Mode: Provisioned (200 RCU, 300 WCU)PITR is Enabled: [2023-01-25T12:28:30Z to 2023-01-25T12:28:30Z]GSI gsi_v: ( HASH v ), Provisioned (10 RCU, 20 WCU), Projecting (ALL), Status: CREATING, Backfilling: YES
LSI: None
Stream: Disabled
Table Class: STANDARD
SSE: Not set
us-east-1>
Second, if you want to know what ddbsh is doing under the covers, use the EXPLAIN command. For example, how did ddbsh add the GSI?
When you issue a SELECT, ddbsh automatically decides how to execute it. To understand that, here’s another example. We create a new table with a PK and RK and EXPLAIN several SELECT statements. The first results in GetItem() the second in Query() and the third in Scan().
Found a good short read about maintaining data integrity in #dynamodb databases using condition expressions in updates.
TL;DR version your records and use a condition expression on the version. A condition expression is different from a key condition – the key condition identifies the item, the condition expression evaluates to true or false after identifying the item. If false, a CCF is thrown!
DynamoDB Condition Checks are a very powerful (and somewhat) misunderstood capability that makes application development much easier.
Consider this most basic “financial” use-case. I have a table that contains customer account balances. Alice has $500 and Bob has $200. Bob wishes to give Alice $100. This is something really simple that screams “RDBMS” but is actually non-trivial with an RDBMS.
We all know that we need transactions because …
But consider this simple twist – How do you prevent Bob’s account balance from going negative?
There is (and I’d love to be proved wrong) no simple SQL solution to this in RDBMS without using one of (a) constraints, (b) triggers, or (c) stored procedures to implement this operation. The easiest is to stick a >= 0 constraint on the account balance. If Bob tries to give Alice more than $200, the update will fail with a constraint violation.
Why do you need one of these things? Consider this (flawed) implementation with an RDBMS.
--
-- WARNING: This implementation is flawed
--
BEGIN;
UPDATE BALANCES
SET BALANCE = BALANCE + 300
WHERE USER = "ALICE";
-- The update below may, or may not update Bob's balance!
UPDATE BALANCES
SET BALANCE = BALANCE - 300
WHERE USER = "BOB" AND BALANCE > 300;
COMMIT;
This will complete successfully with the first update giving Alice the money and the second succeeding without doing anything!
This is where the Condition Check in DynamoDB comes along. Consider this with DynamoDB
Notice that there is the update expression that updates the balance down by $100, but also a condition check that requires an item to exist that meets the requirement
owner = "bob" and balance > 100
Nifty!
In SQL, different databases give you constructs like this (from SQLServer)
UPDATE BALANCES
SET BALANCE = BALANCE - 300
WHERE OWNER = "Bob" AND BALANCE > 300;
IF @@ROWCOUNT = 0 ...
You’d then be able to decide whether or not you actually updated a row, and take corrective action.
DynamoDB UpdateItem() provides a condition check expression (even without a transaction).
us-east-1> select * from balances;
{balance: 100, owner: bob}
{balance: 600, owner: alice}
us-east-1> update balances set balance = balance - 200 where owner = "bob" and balance > 200;
UPDATE (0 read, 0 modified, 1 ccf)
us-east-1>
The NoSQL “single-table” design pattern appears to be a polarizing topic with strong opinions for and against it. As best as I can tell, there’s no good reason for that!
I did a talk at AWS re:Invent last week along with Alex DeBrie. The talk was about deploying modern and efficient data models with Amazon DynamoDB. One small part of the talk was about the “single-table” design pattern. Over the next couple of days I have been flooded with questions about this pattern. I’m not really sure what all the hoopla is about this pattern, and why there is so much passion and almost religious fervor around this topic.
With RDBMS there are clearly defined benefits and drawbacks with normalization (and denormalization). Normalization and denormalization are an exercise in trading off between a well understood set of redundancies and anomalies, and runtime complexity and cost. When you normalize your data, the only mechanism to get it “back together” is using a “join”.
If you happen to use a database that doesn’t support joins, or if joins turn out to be expensive, you may prefer to accept the redundancies and anomalies that come with denormalization. This has been a long established pattern, for example in the analytics realm.
The “single-table” design pattern extends traditional RDBMS denormalization in three interesting ways. First, it quite often uses non-atomic datatypes that are not allowed in the normalized terminology of Codd, Date, and others. Second, makes use of the flexible schema support in NoSQL databases to commingle data from different entities in a single table. Finally, it uses data colocation guarantees in NoSQL databases to minimize the number of blocks read, and the number of API calls required in fetching related data.
Here’s what I think these options look like in practice.
First, this is a normalized schema with three tables. When you want to reconstruct the data, you join the tables. There are primary and foreign key constraints in place to ensure that data is consistent.
The next option is the fully denormalized structure where data from all tables is “pre-joined” into a single table.
The single-table schema is just slightly different. Data for all entities are commingled into a single table.
Application designers, and data modelers should look at their specific use-cases and determine whether or not they want to eliminate redundancies and inconsistencies and pay the cost of joins (or performing the join themselves in multiple steps if the database doesn’t support it), or denormalize and benefit from lower complexity and sometimes lower cost!
The other thing to keep in mind is that nothing in the single table design pattern requires you to bring all entities into a single table. A design where some entities are combined into a single table, coexists perfectly with others that are not.
In 2011, Ken Rugg and I were having a number of conversations around CAP Theorem and after much discussion, we came up with the following succinct inequality. It was able to help us much better speak to the issue of what constituted “availability”, “partition tolerance”, and “consistency”. It also confirmed our suspicions that availability and partition tolerance were not simple binary attributes; Yes or No, but rather that they had shades of gray.
I’ve been following the blockchain ecosystem for some time now largely because it strikes me as yet another distributed database architecture, and I dream about those things.
For some time now, I’ve been wondering what to do after Tesora and blockchain was one of the things I’ve been looking at as a promising technology but I wasn’t seeing it. Of late I’ve been asking people who claim to be devotees at the altar of blockchain what they see as the killer app. All I hear are a large number of low rumbling sounds.
And then I saw this article by Jamie Burke of Convergence.vc and I feel better that I’m not the only one who feels that this emperor is in need of a wardrobe.
Let’s be clear, I absolutely agree that bitcoin is a wonderful use of the blockchain technology and it solves the issue of trust very cleverly through proof of work. I think there is little dispute of elegance of this solution.
But once we go past bitcoin, the applications largely sound and feel like my stomach after eating gas station sushi; they sound horrible and throw me into convulsions of pain.
In his article, Jamie Burke talks of 3d printing based on a blockchain sharded CAD file. I definitely don’t see how blockchain can prevent the double-spend (i.e. buy one Yoda CAD file, print 10,000).
Most of the blockchain ideas I’m seeing are things which are attempting to piggy-back on the hot new buzzword and where blockchain is being used to refer to “secure and encrypted database”. After all, there’s a bunch of crypto involved and there’s data stored there right? so it must be a secure encrypted database.
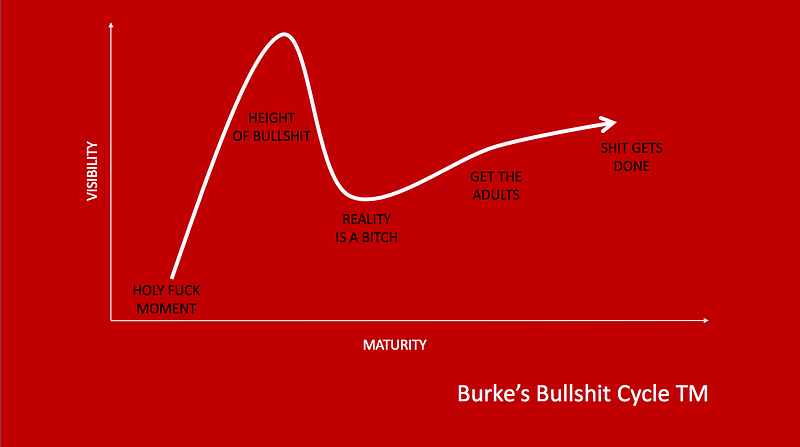
To which I say, Bullshit!
P.S. Oh, the irony. This blog post references a blog post with a picture labeled “Burke’s Bullshit Cycle”, and the name of this blog is hypecycles.com.
I think the future for NoSQL isn’t as bright as a lot of pundits would have you believe. Yes, Yes, I know that MongoDB got a $1.2 billion valuation. Some other things to keep in mind.
In the heyday of OODBMS, XML DB, and OLAP/MDX, there was similar hype about those technologies.
Today, more and more NoSQL vendors are trying to build “SQL’isms” into their products. I often hear of people who want a product that has the scalability of NoSQL with transactions and a standard query language. Yes, we have that; it is called a horizontally scalable RDBMS!
Technologies come and technologies go but the underlying trends are worth understanding.
Just to be clear, this was with standard MySQL, InnoDB, and with machines in Amazon’s cloud (AWS).
The data was inserted using standard SQL INSERT statements and can be queried immediately using SQL as well. All standard database stuff, no NoSQL tomfoolery going on.
This kind of high ingest rate has long been considered to be out of the reach of traditional databases; not at all true.
I just posted an article comparing parallel databases to sharding on the ParElastic blog at http://bit.ly/JaMeVr
It was motivated by the fact that I’ve been asked a couple of times recently how the ParElastic architecture compares with sharding and it occurred to me this past weekend that
“Parallel Database” is a database architecture but sharding is an application architecture
Two days ago, someone called ‘nomoremongo’ posted this on Y Combinator News.
Several people (me included) stumbled upon the article, read it, and took it at face value. It’s on the Internet, it’s got to be true, right?
No, seriously. I read it, and parts of it resonated with my understanding of how MongoDB works. I saw some of the “warnings” and they seemed real. I read this one (#7) and ironically, this was the one that convinced me that this was a true post.
**7. Things were shipped that should have never been shipped**
Things with known, embarrassing bugs that could cause data
problems were in "stable" releases--and often we weren't told
about these issues until after they bit us, and then only b/c
we had a super duper crazy platinum support contract with 10gen.
The response was to send up a hot patch and that they were
calling an RC internally, and then run that on our data.
Who but a naive engineer would feel this kind of self-righteous outrage 😉 I’ve shared this outrage at some time in my career, but then I also saw companies ship backup software (and have a party) when they knew that restore couldn’t possibly work (yes, a hot patch), software that could corrupt data in pretty main stream circumstances (yes, a hot patch before anyone installed stuff) etc.,
I spoke with a couple of people who know about MongoDB much better than I do and they all nodded about some of the things they read. The same article was also forwarded to me by someone who is clearly knowledgeable about MongoDB.
OK, truth has been established.
Then I saw this tweet.
Which was odd. Danny doesn’t usually swear (well, I’ve done things to him that have made him swear and a lot more but that was a long time ago). Right Danny?
Well, he had me at the “Start thinking for yourself”. But then he went off the meds, “MongoDB is the next MySQL”, really …
I think there’s a kernel of truth in the MongoDB rant. And it is certainly the case that a lot of startups are making dumb architectural decisions because someone told them that “MongoDB was web-scale”, or that “CAP Theorem told them that databases were dead”.
Was this a hoax? I don’t know. But it was certainly a reminder that all scams don’t originate in Nigeria, and don’t begin by telling me that I could make a couple of billion dollars if I just put up and couple of thousand.
Having read the article, my only question to these folks is “why do it”?
Let’s begin by saying that we should discount all one time costs related to data migration. They are just that, one time migration costs. However monumental, if you believe that the final outcome is going to justify it, grin and bear the cost.
But, once you are in the (promised) MongoDB land, what then?
The things that this author believes that they will miss are:
maturity
tools
query expressiveness
transactions
joins
case insensitive indexes on text fields
Really, and you would still roll the dice in favor of a NoSQL science project. Well, then the benefits must be really really awesome! Let’s go take a look at what those are. Let’s take a look at what those are:
MongoDB is free
MongoDB is fast
Freedom from rigid schemas
ObjectID’s are expressive and handy
GridFS for distributed file storage
Developed in the open
OK, I’m scratching my head now. None of these really blows me away. Let’s look at these one at a time.
MongoDB is free
So is PostgreSQL and MySQL
MongoDB is fast
So are PostgreSQL and MySQL if you put them on the same SSD and multiple HDD’s like you claim you do with MongoDB
Freedom from rigid schemas
I’ll give you this one, relational databases are kind of “old school” in this department
ObjectID’s are expressive and handy
Elastic Transparent Sharding schemes like ParElastic overcome this with Elastic Sequences which give you the same benefits. A half-way decent developer could do this for you with a simple sharded architecture.
GridFS for distributed file storage
Replication anyone?
Developed in the open
Yes, MongoDB is free and developed in the open like a puppy is “free”. You just told us all the “costs” associated with this “free puppy”
So really, why do people use MongoDB? I know there are good circumstances where MongoDB will whip the pants off any relational database but I submit to you that those are the 1%.
To this day, I believe that the best description of MongoDB is this one:
A common myth that has been perpetrated is that relational database do not scale beyond two or three nodes. That, and the CAP Theorem are considered to be the reason why relational databases are unscalable and why NoSQL is the only feasible solution!
I ran into a very thought provoking article that makes just this case yesterday. You can read that entire post here. In this post, the author Srinath Perera provides an interesting template for choosing the data store for an application. In it, he makes the case that relational databases do not scale beyond 2 or 5 nodes. He writes,
The low scalability class roughly denotes the limits of RDBMS where they can be scaled by adding few replicas. However, data synchronization is expensive and usually RDBMSs do not scale for more than 2-5 nodes. The “Scalable” class roughly denotes data sharded (partitioned) across many nodes, and high scalability means ultra scalable systems like Google.
In 2002, when I started at Netezza, the first system I worked on (affectionately called Monolith) had almost 100 nodes. The first production class “Mercury” system had 108 nodes (112 nodes, 4 spares). By 2006, the systems had over 650 nodes and more recently much larger systems have been put into production. Yet, people still believe that relational databases don’t scale beyond two or three nodes!
Systems like ParElastic (Elastic Transparent Sharding) can certainly scale to much more than two or three nodes, and I’ve run prototype systems with upto 100 nodes on Amazon EC2!
Srinath’s post does contain an interesting perspective on unstructured and semi-structured data though, one that I think most will generally agree with.
I’ve been working on a series of blog posts (for the ParElastic blog http://www.parelastic.com/blog/) and the first of them is about building elastic applications.
You can read it here http://www.parelastic.com/database-architectures/engineering-an-elastic-application/
I have long believed that databases can be successfully deployed in virtual machines. Among other things, that is one of the central ideas behind ParElastic, a start-up I helped launch earlier this year. Many companies (Amazon, Rackspace, Microsoft, for example) offer you hosted databases in the cloud!
But yesterday I read this post in RWW. This article talks about a report published by Principled Technologies in July 2011, a report commissioned by Intel, that
tested 12 database applications simultaneously – and all delivered strong and consistent performance. How strong? Read the case study, examine the results and testing methodology, and see for yourself.
Unfortunately, I believe that discerning readers of this report are more likely to question the conclusion(s) based on the methodology. What do you think?
A Summary of the Principled Technologies Report
In a nutshell, this report seeks to make the case that industry standard servers with virtualization can in fact deliver the performance required to run business critical database applications.
It attempts to do so by running Vware vSphere 5.0 on the newest four socket Intel Xeon E7-4870 based server and hosting 12 database applications each of which has an 80GB database in its own virtual machine. The Intel Xeon E7-4870 server is a 10 core processor with two hardware threads per core. It was clocked at 2.4GHz and 1TB of RAM (64 modules each of which had 16GB). The storage in this server was 2 disks, each of which was 146GB in size (10k SAS). In addition, an EMC Clarriion Fibre Channel SAN with some disks configured in RAID0. In total they configured 6 LUN’s each of which was 1066GB (over a TB each). They VM’s ran Windows Server 2008 R2, and SQL Server 2008 R2.
The report claims that the test that was performed was “Benchmark Factory’s TPC-H like workload”. Appendix B somewhat (IMHO) misleadingly calls this “Benchmark Factory TPC-H score”.
The result is that these twelve VM’s running against an 80GB database were able to consistently process in excess of 10,000 queries per hour each.
A comparison is made to the Netezza whitepaper that claims that the TwinFin data warehouse appliance running the “Nationwide Financial Services” workload was able to process around 2,500 queries per hour and a maximum of 10,000 queries per hour.
The report leaves the reader to believe that since the 12 VM’s in the test ran consistently more than 10,000 queries per hour, business critical applications can in fact be deployed in virtualized environments and deliver good performance.
The report concludes therefore that business critical applications can be run on virtualized platforms, deliver good performance, and reduce cost.
My opinion
While I entirely believe that virtualized database servers can produce very good performance, and while I entirely agree with the conclusion that was reached, I don’t believe that this whitepaper makes even a modestly credible case.
I ask you to consider this question, “Is the comparison with Netezza running 2,500 queries per hour legitimate?”
Without digging too far, I found that the Netezza whitepaper talks of a data warehouse with “more than 4.5TB of data”, 10 million database changes per day, 50 concurrent users at peak time and 10-15 on an average. 2,500 qph with a peak of 10k qph at month end, 99.5% completing in under one minute.
Based on the information disclosed, this comparison does not appear to be valid. Note well that I am not saying that this comparison is invalid, rather that the case has not been made sufficiently to justify it.
An important reason for my skepticism is that when processing database operations like joins between two tables, doubling the data volume quadruples the amount of computation that may be required. If you are performing three table joins, doubling the data increases the computation involved may be as much as eight times. This is the very essence of the scalability challenge with databases!
I get an inkling that this may not be a valid comparison when we look at Appendix B that states that the total test time was under 750 seconds in all cases.
This feeling is compounded when I don’t see how many concurrent queries are run against each database. Single user database performance is a whole lot better and more predictable than multi-user performance. The Netezza paper specifically talks about the multi-user concurrency performance not the single-user performance.
Reading very carefully, I did find a mention that a single server running 12 VM’s hosted the client(s) for the benchmark. Since ~15k queries were completed in under 750s, we can say that each query lasted about 0.05s. Now, those are really really short queries. Impressive but not what I would generally consider to be in the kinds of workloads that one would expect Netezza to be deployed. The Netezza report does clearly state that 99.5% completed in under one minute, which leads me to conclude that the queries being run in the subject benchmark are at least two orders of magnitude away!
Conclusion
Virtualized environments like Amazon EC2, Rackspace, Microsoft Azure, and VMWare are perfectly capable of running databases and database applications.One need only look at Amazon RDS (now with MySQL and Oracle), database.com, SQL Azure, and offerings like that to realize that this is in fact the case!
However, this report fails to make a compelling case for this. By making a comparison to a different whitepaper and simply relating the results to the “queries per hour” in the other paper causes me to question the methodology. Once readers question the method(s) used to reach a conclusion, they are likely to question the conclusion itself.
Therefore, I don’t believe that this report achieves what it set out to do.
References
You can get a copy of the white paper here, a link to scribd, or here, a link to the PDF on RWW.
This case study references a Netezza whitepaper on concurrency, which you can get here. The Netezza whitepaper is “CONCURRENCY & WORKLOAD MANAGEMENT IN NETEZZA”, and prepared by Winter Corp and sponsored by Netezza.
I have also archived copies of the two documents here and here.
A link to the TPC-H benchmark can be found on the TPC web site here.
Disclosure
In the interest of full disclosure, in the past I was an employee of Netezza, a company that is referenced in this report.
Oracle’s announcement of a NoSQL solution at Oracle Open World 2011 has produced a fair amount of discussion. Curt Monash blogged about it some days ago, and so did Dan Abadi. A great description of the new offering (Dan credits it to Margo Seltzer) can be found here or here. I think the announcement, and this whitepaper do in fact bring something new to the table that we’ve not had until now.
First, the Oracle NoSQL solution extends the notion of configurable consistency in a surprising way. Solutions so far had ranged from synchronous consistency to eventual consistency. But, all solutions did speak of consistency at some point in time. Eventual consistency has been the minimum guarantee of other NoSQL solutions. The whitepaper referenced above makes this very clear and characterizes this not in terms of consistency but durability.
Oracle NoSQL Database also provides a range of durability policies that specify what guarantees the system makes after a crash. At one extreme, applications can request that write requests block until the record has been written to stable storage on all copies. This has obvious performance and availability implications, but ensures that if the application successfully writes data, that data will persist and can be recovered even if all the copies become temporarily unavailable due to multiple simultaneous failures. At the other extreme, applications can request that write operations return as soon as the system has recorded the existence of the write, even if the data is not persistent anywhere. Such a policy provides the best write performance, but provides no durability guarantees. By specifying when the database writes records to disk and what fraction of the copies of the record must be persistent (none, all, or a simple majority), applications can enforce a wide range of durability policies.
2. It sets forth a very specific set of use-cases for this product.There has been much written by NoSQL proponents about its applicability in all manners of data management situations. I find this section of the whitepaper to be particularly fact based.
The Oracle NoSQL Database, with its “No Single Point of Failure” architecture is the right solution when data access is “simple” in nature and application demands exceed the volume or latency capability of traditional data management solutions. For example, click-stream data from high volume web sites, high-throughput event processing, and social networking communications all represent application domains that produce extraordinary volumes of simple keyed data. Monitoring online retail behavior, accessing customer profiles, pulling up appropriate customer ads and storing and forwarding real-time communication are examples
of domains requiring the ultimate in low-latency access. Highly distributed applications such as real-time sensor aggregation and scalable authentication also represent domains well-suited to Oracle NoSQL Database.
Several have also observed that this position is in stark contrast to Oracle’s previous position on NoSQL. Oracle released a whitepaper written in May 2011 entitled “Debunking the NoSQL Hype”. This document has been removed from Oracles website. You can, however, find cached copies all over the internet. Ironically, the last line in that document reads,
Go for the tried and true path. Don’t be risking your data on NoSQL databases.
With all that said, this certainly seems to be a solution that brings an interesting twist to the NoSQL solutions out there, if nothing else to highlight the shortcomings of existing NoSQL solutions.
[2011-10-07] Two short updates here.
There has been an interesting exchange on Dan Abadi’s blog (comments) between him and Margo Seltzer (the author of the whitepaper) on the definition of eventual consistency. I subscribe to Dan’s interpretation that says that perpetually returning to T0 state is not a valid definition (in the limit) of eventual consistency.
Some kind soul has shared the Oracle “Debunking the NoSQL Hype” whitepaper here. You have to click download a couple of times and then wait 10 seconds for an ad to complete.











{kind=link}